StepFun AI推出开源音频编辑模型Step-Audio-EditX
StepFun AI推出了一项开源音频编辑模型Step-Audio-EditX,该模型旨在提供强大的音频编辑功能,包括音频剪辑、混音、降噪等,该模型采用深度学习技术,能够自动化处理音频数据,提高音频编辑效率和质量,该模型的开源性质使得开发者可以自由地对其进行修改和优化,进一步推动音频编辑技术的发展。

StepFun AI 最近推出了其开源音频编辑模型 Step-Audio-EditX,这款拥有30亿参数的创新模型让音频编辑如同文本编辑般直观且高度可控。它通过将音频信号的修改任务转化为逐字令牌操作,显著简化了富有表现力的语音内容调整过程。
当前主流的零样本文本到语音(TTS)系统在情感表达、语调风格、口音特征以及音色控制方面仍存在局限性。虽然能够生成自然流畅的语音,却难以精准满足用户的个性化需求。以往的研究多依赖额外编码模块或复杂网络结构来分离这些因素,而 Step-Audio-EditX 则另辟蹊径,通过优化训练数据和目标函数实现精细控制。
该模型采用双代码本标记机制,将语音信号分解为两个并行的令牌流:一个以16.7Hz 的频率捕捉语言内容信息,另一个以25Hz 的频率记录语义与韵律特征。模型在融合了文本和音频令牌的混合语料库上进行训练,使其具备同时处理文字与声音标记的能力。
其核心技术之一是引入大边距学习策略,在后续训练阶段使用合成的大边距三元组和四元组样本增强模型判别与生成能力。依托来自约6万名说话者的高质量语音数据,Step-Audio-EditX 在情感迁移和风格变换任务中展现出卓越性能。同时,模型还结合人类评分反馈与偏好数据,利用强化学习进一步提升输出语音的自然度与准确性。
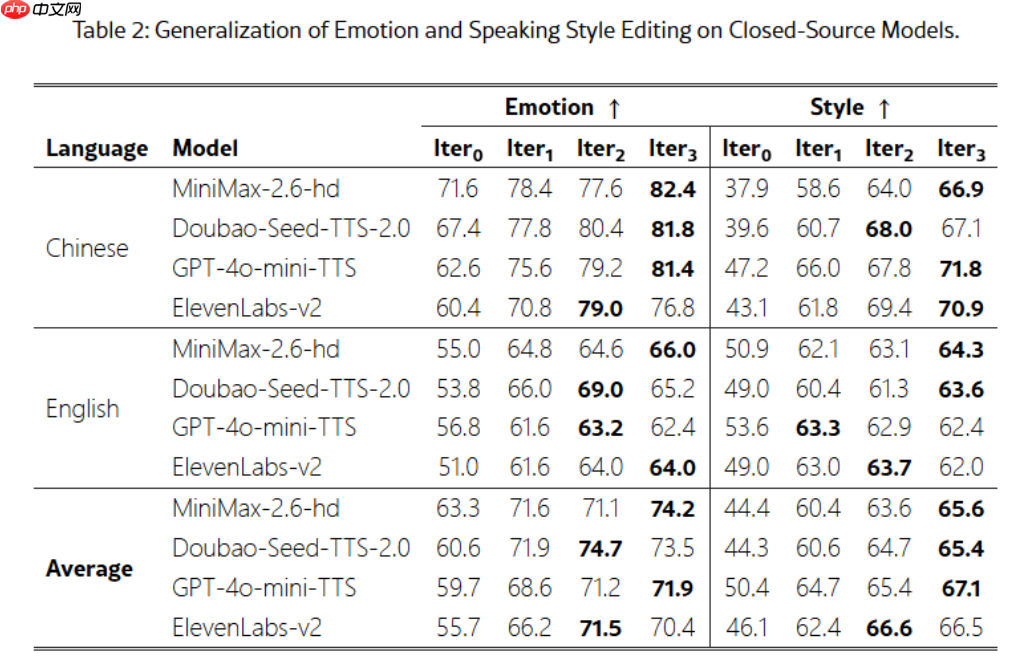
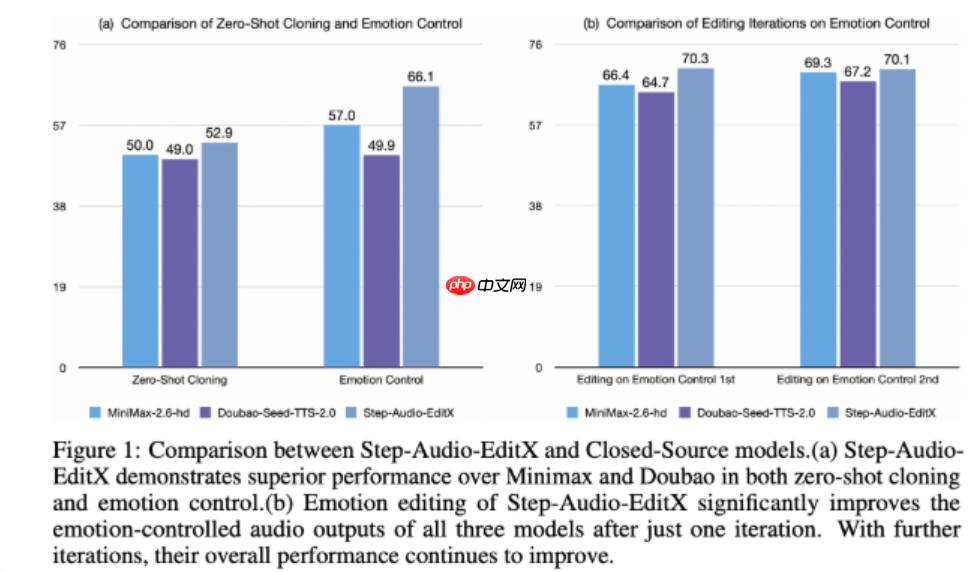
为全面评估模型效果,研究团队构建了名为 Step-Audio-Edit-Test 的评测基准,并采用 Gemini2.5Pro 作为自动评判引擎。实验结果表明,经过多轮迭代编辑后,模型在情感表达和说话风格还原上的准确率显著提高。更值得注意的是,Step-Audio-EditX 还可作为增强工具,有效改善其他闭源 TTS 系统输出的音频质量,为未来音频编辑技术的发展开辟了全新路径。
网友留言(0 条)