360开源视觉语言对齐模型FG-CLIP2揭秘,跨模态交互的新里程碑
近日,开源视觉语言对齐模型 FG-CLIP2 由 360 公司推出,该模型采用先进的视觉和语言对齐技术,实现了图像与文本之间的精准匹配,FG-CLIP2 模型具备强大的泛化能力和鲁棒性,可广泛应用于图像标注、视觉问答、多媒体内容检索等领域,其开源特性有助于科研人员和企业快速应用并优化模型,推动视觉语言对齐技术的发展。
360 集团近期宣布开源其全新视觉语言对齐模型 fg-clip2。该模型在包括长短文本图文检索、目标检测等在内的29项权威公开基准测试中,全面超越了来自google的siglip 2以及meta的metaclip2。

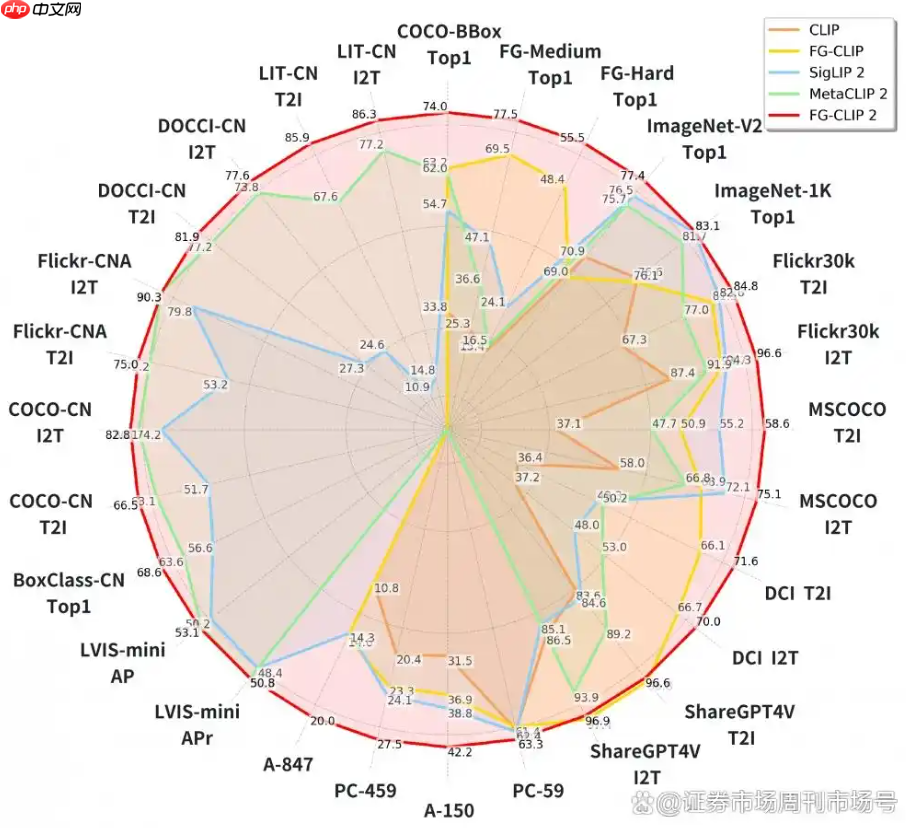
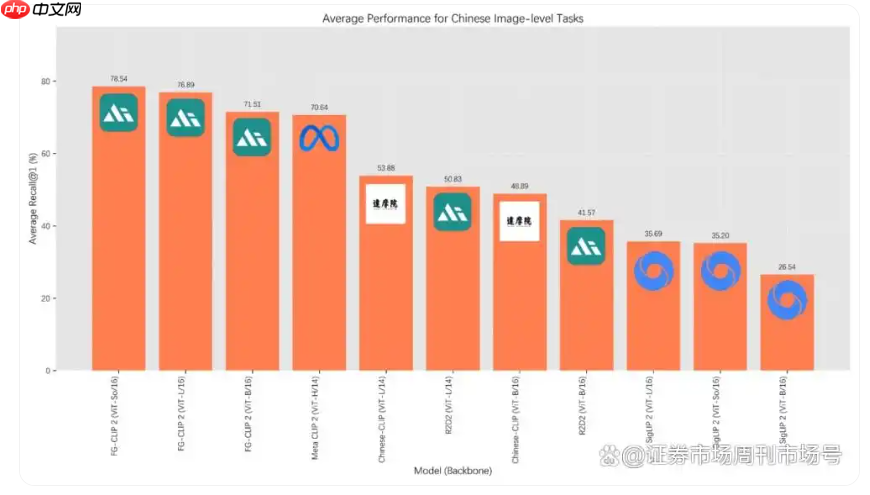
据官方介绍,FG-CLIP2 在模型架构层面实现了三大核心突破:首先,采用层次化对齐结构,使模型能够模仿人类视觉系统,同时捕捉整体场景与局部细节,实现从“看见”到“看清”的质变。
其次,引入动态注意力机制,让模型可智能识别并聚焦图像中的关键区域,在降低计算开销的同时显著提升细节感知精度。最后,通过双语协同优化策略,从根本上缓解了中英文语义理解不对称的问题,达成真正的中英双语原生支持能力。
FG-CLIP2 的训练依托于自研的大规模高质量数据集 FineHARD。该数据集不仅涵盖精细的全局图像描述和千万级局部区域标注,还首次引入由大模型生成的“难负样本”,进一步增强了模型的判别能力。
网友留言(0 条)