月之暗面发布混合线性注意力架构,Kimi Linear技术详解
最近,月之暗面团队发布了名为Kimi Linear的混合线性注意力架构,这一架构结合了线性注意力机制和其他技术,旨在提高处理大规模数据集时的效率和性能,Kimi Linear架构的发布对于人工智能和自然语言处理领域的发展具有重要意义,有望为相关应用带来更快的响应速度和更高的准确性。


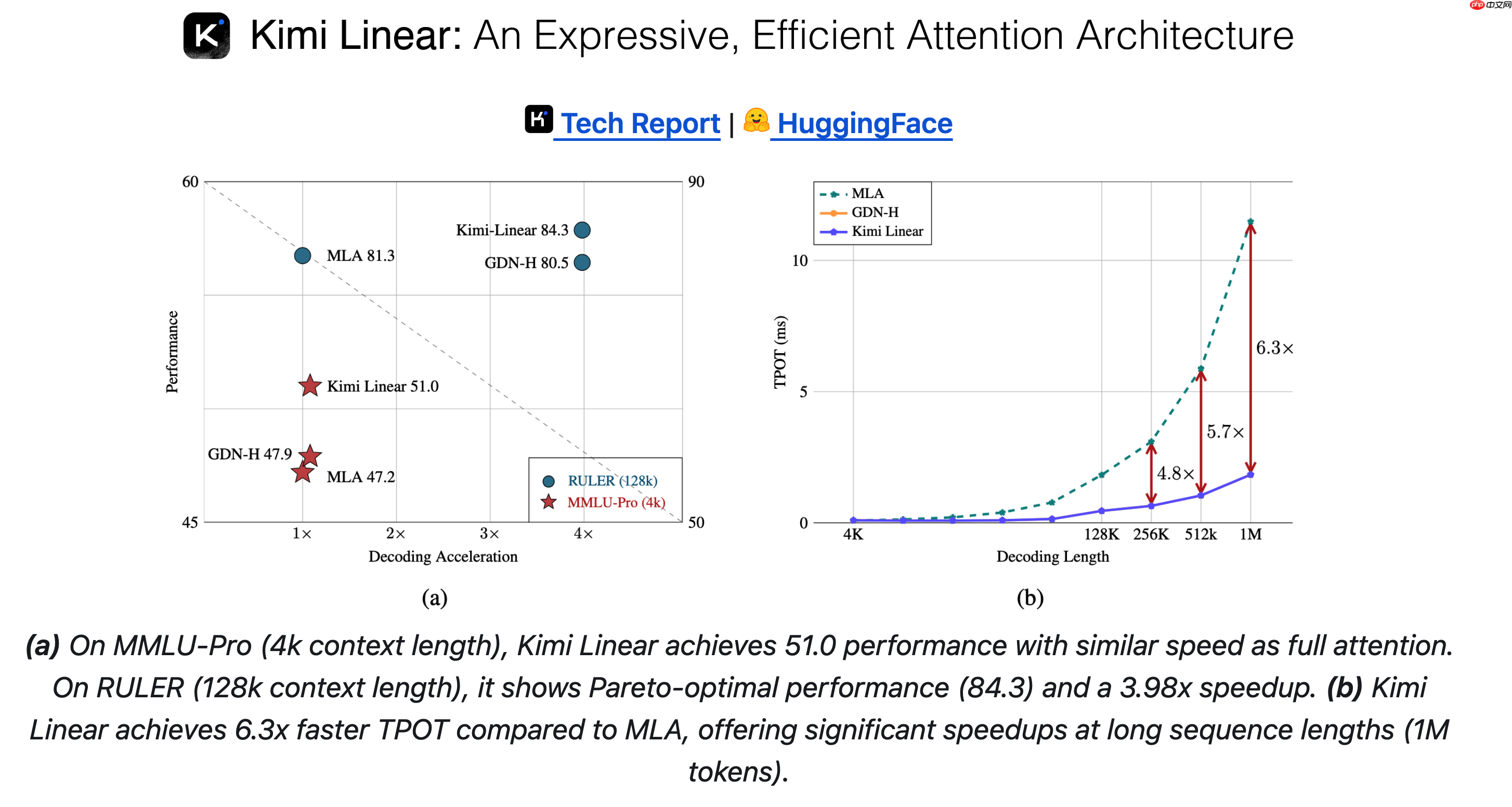
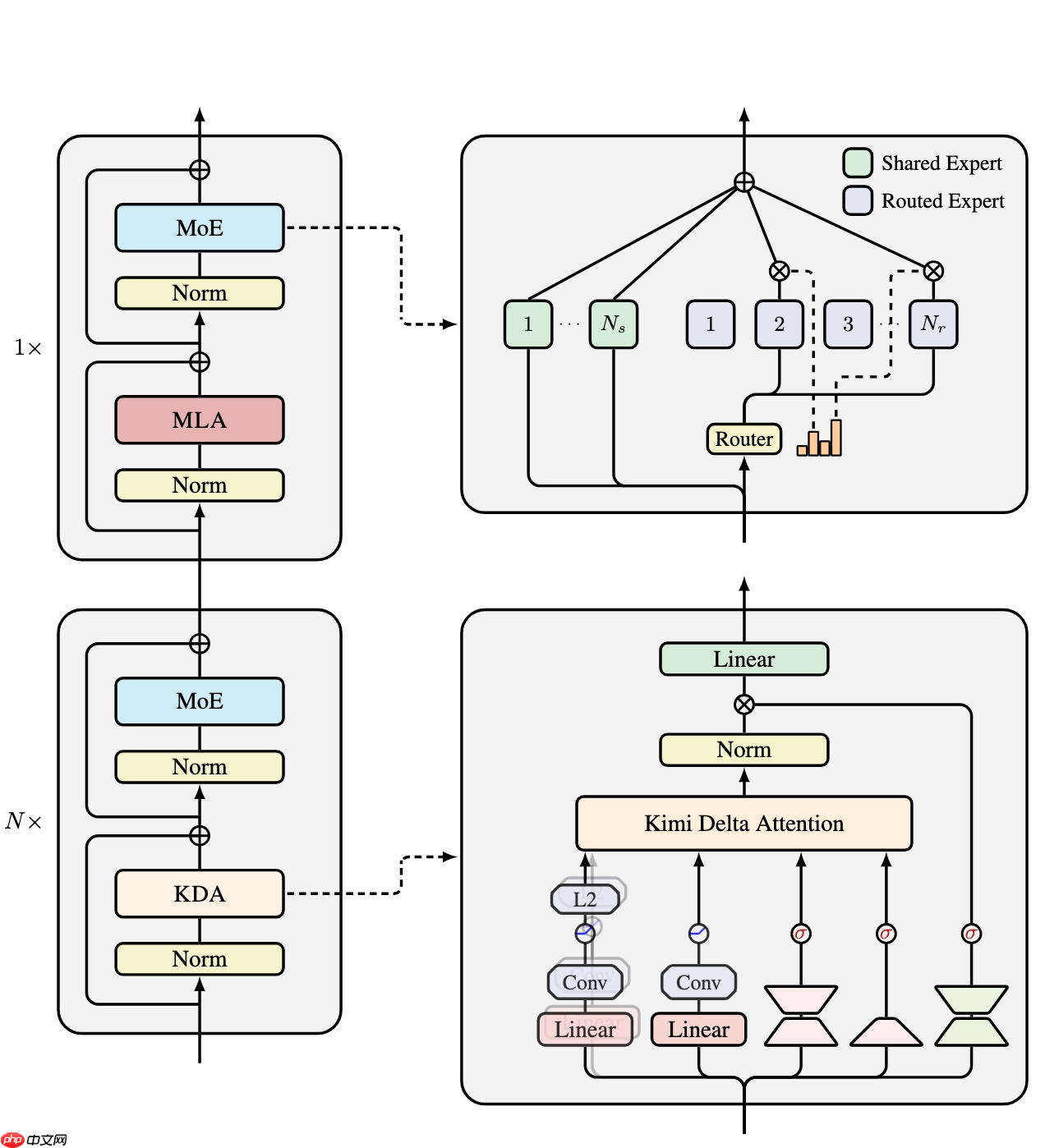
月之暗面近日推出了名为“Kimi Linear”的新型混合线性注意力架构,宣称在短序列、长序列以及强化学习(RL)等多种扩展任务中表现优于传统的全注意力机制。该架构的核心组件是Kimi Delta Attention(KDA),它是Gated DeltaNet的升级版本,通过引入更高效的门控结构,优化了有限状态RNN中记忆信息的利用效率。
Kimi Linear由三个Kimi Delta Attention(KDA)模块与一个全局MLA模块组合而成。其中,KDA在原有Gated DeltaNet基础上进行了改进,采用细粒度的门控策略,有效压缩了RNN状态的记忆开销,提升了模型的可扩展性与运行效率。
根据官方公布的数据,在处理长达1百万token的上下文时,Kimi Linear将KV cache的内存占用减少了75%,解码吞吐量最高提升达6倍,同时TPOT(Time Per Output Token)相较于MLA实现了6.3倍的加速效果。

Kimi Linear 技术报告:https://www.php.cn/link/7666534473231043db00bea461f55d33
下一篇 >>
网友留言(0 条)