信息论基础上的大模型强化学习微调框架研究
本研究提出了一种基于信息论的大模型强化学习微调框架,该框架旨在通过信息论的理论指导,优化强化学习模型的性能,通过微调框架,软件能够在大规模数据上进行训练,并利用信息论原理对模型进行精细化调整,这一创新方法有望提高强化学习模型的适应性和泛化能力,为机器学习和人工智能领域的发展提供新的思路和方法。
中国科学院软件研究所天基综合信息系统全国重点实验室的研究团队围绕大语言模型(llms)在复杂推理任务中的性能优化问题,提出了一种创新的强化微调框架——learning to think (l2t)。该框架基于信息论原理,致力于在提升模型推理能力的同时优化计算效率,为大语言模型在实际场景中的高效推理提供了全新的技术思路。

相关研究成果论文 Learning to Think: Information-Theoretic Reinforcement Fine-Tuning for LLMs 已被人工智能领域顶级会议NeurIPS 2025接收并发表。论文的第一作者分别为博士生王婧瑶、副研究员强文文以及博士生宋泽恩。
近年来,随着大语言模型能力的持续增强,其应用已逐步从简单的文本生成扩展至需要多步逻辑推导的高难度任务。研究团队指出,当前大多数LLMs在处理此类复杂推理任务时,通常仅以最终输出结果作为奖励信号进行反馈训练,忽视了对中间推理过程的有效监督。这种机制容易导致模型生成大量无意义或重复的推理步骤,不仅消耗更多计算资源,还可能影响最终的推理准确性。
为解决这一问题,L2T框架首先将推理任务重新建模为一个多轮次、层次化的对话结构,并引入一种基于信息增益的过程奖励机制。该机制通过量化每一轮推理所带来的情报增量,结合改进的GRPO算法对模型策略进行精细化调整,有效激励关键推理行为,抑制无效或冗余输出,从而实现对整个推理路径的动态调控。
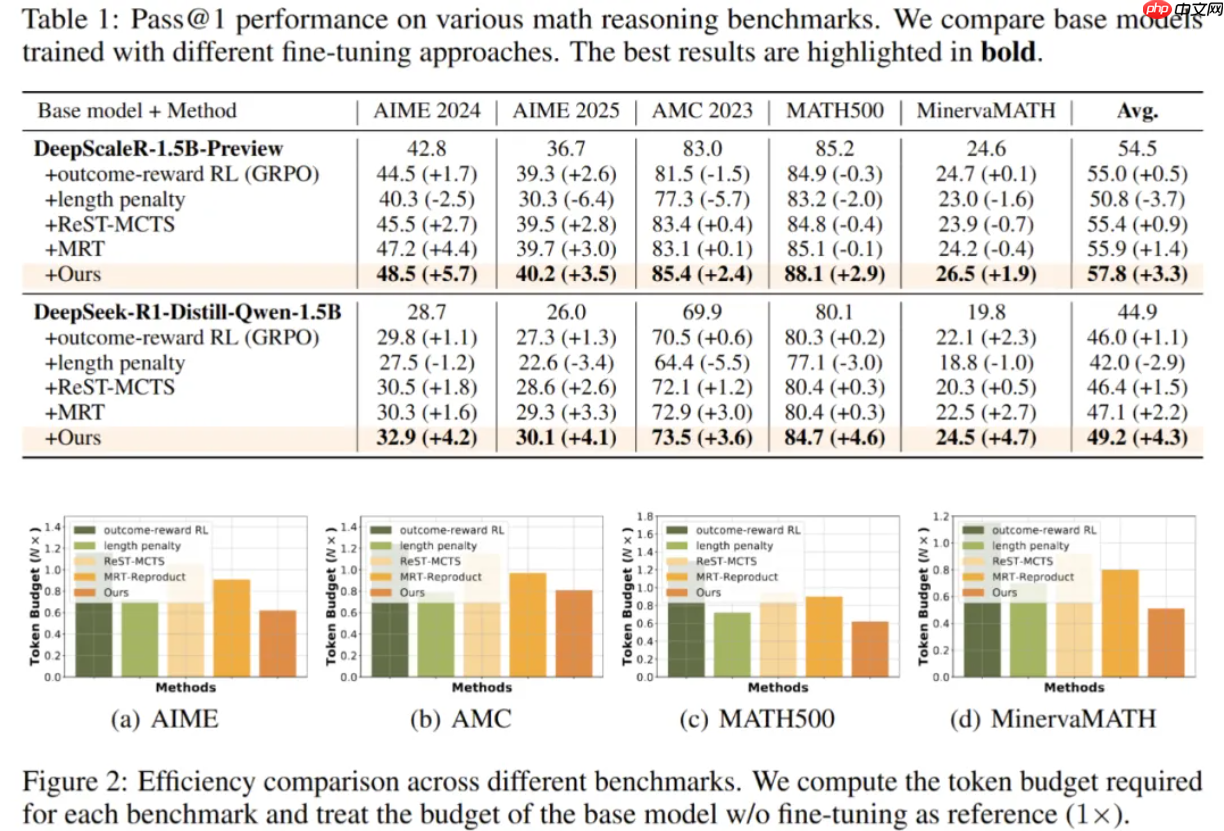
在AIME、AMC和HumanEval等多个主流推理基准上的实验表明,L2T在多种规模的基础模型(如DeepScaleR-1.5B-Preview、DeepSeek-R1-Distill-Qwen-1.5B等)上均展现出一致且显著的性能优势。与传统依赖结果奖励的方法相比,L2T在准确率方面提升了超过3.2%,同时推理过程的token使用效率提高了一倍;相较于其他过程奖励方法,L2T仍能实现约2%的准确率增益,效率提升达1.2倍。此外,在跨任务综合评估中,L2T在不同难度等级的任务上平均准确率提升接近3%,并在各种token预算条件下均保持稳定的领先表现。
网友留言(0 条)